Le principe général d’un intervalle de confiance consiste à déterminer, à partir de ce qui a été observé dans un sous-échantillon, un intervalle dans lequel la grandeur que l’on étudie, au sein de la population dont est extrait l’échantillon, a de fortes chances de se situer. En l’occurrence, il s’agit de déterminer un intervalle, connaissant la proportion p observée dans l’échantillon, au sein duquel la proportion π réelle de la population étudiée se situe avec une probabilité égale à une valeur fixée à l’avance, usuellement 95 %, et notée 1-α.
Il s’agit donc de rechercher a et b tels que p[a ≤ π ≤ b]=1-α. α correspond au risque d’erreur que nous acceptons de prendre. Nous pouvons interpréter cet intervalle de confiance par “il y a une probabilité de 1-α pour que π soit compris entre a et b”.
Dans la suite de notre propos, nous nous situerons dans le cadre d’un échantillonnage aléatoire simple issu d’une population infinie. Dans les faits, les populations que nous étudions ne sont pas infinies mais sont suffisamment grandes comparées à la taille de nos échantillons (le plus souvent, il s’agit de populations de plusieurs millions d’individus tandis que nos enquêtes portent sur quelques milliers de personnes au plus) pour que nous puissions considérer qu’il s’agit d’une population infinie. Des corrections sont techniquement possibles. En l’espèce, nous pouvons négliger cet aspect.
Loi Binomiale
Nous noterons n la taille de notre échantillon. Le nombre d’individus observés, parmi les n enquêtés, présentant le caractère étudié est donc égale à np. Ce nombre np suit ce que l’on nomme une loi Binomiale de paramètre n et π. Il s’agit d’une loi discrète et non continue. En effet, np ne peut être qu’un nombre entier. Si 100 personnes ont été enquêtées, 12 ou encore 58 parmi elles peuvent présenter un caractère donné, mais cela ne peut être 12,5 ou 58,3. Le caractère discret de la loi binomiale implique que le calcul d’un intervalle de confiance exact est relativement compliqué et il a amené à de vives discussions parmi les statisticiens sur la manière adéquate de procéder ( [1], [2], [3], [4], [5], [6]).
Cependant, dès lors que l’échantillon est suffisamment grand, il est possible d’avoir recours au théorème central limite qui permet de simplifier le calcul, p pouvant être alors approximé par une loi Normale.
De plus, dans le cadre d’un tirage aléatoire simple avec remise (ce qui correspond à une population-mère infinie), nous pouvons considérer que la sélection de chaque individu de l’échantillon est indépendante des autres individus sélectionnés. Il en résulte alors que le meilleur estimateur possible de la proportion réelle π est la proportion observée p. D’un point de vue plus formel, p est un estimateur sans biais, efficace et convergent de π et correspond à l’estimateur obtenu par la méthode du maximum de vraisemblance ( [7], p. 164, 166, 169 et 175).
Plusieurs méthodes ont été développées pour calculer l’intervalle de confiance d’une proportion. Nous ne présenterons ici que quatre d’entre elles :
- la méthode standard traditionnelle, nommée méthode asymptotique ou bien encore méthode WALD par VOLLSET ( [8]) et d’autres auteurs à sa suite ;
- la méthode de score ou méthode WILSON ( [9]), encore appelée méthode de l’ellipse ;
- la méthode WALD avec correction de continuité ( [10]) ;
- la méthode de score de WILSON avec correction de continuité ( [11], [8]).
Ces quatre méthodes sont disponibles dans la feuille de calcul jointe.
Des méthodes plus complexes ont également été proposées mais elles sont plus difficiles à mettre en œuvre. Par ailleurs, le gain apporté à les utiliser est le plus souvent limité dans le cadre d’un usage courant.
Méthode standard (Wald)
Selon le théorème central limite, la moyenne expérimentale d’une répétition d’expériences identiques converge, quand n augmente, vers une loi Normale. Il en résulte que, pour n suffisamment grand, nous pouvons considérer que p suit une loi Normale de moyenne π et d’écart-type ![]() . Usuellement, on considère que cette approximation est valable pour n supérieur à 30 ( [12], p. III-8). D’autres auteurs préconisent que l’on ait observé au moins 5 succès et 5 échecs : soit np≥5 et n(1-p)≥5 ( [13], p. 310).
. Usuellement, on considère que cette approximation est valable pour n supérieur à 30 ( [12], p. III-8). D’autres auteurs préconisent que l’on ait observé au moins 5 succès et 5 échecs : soit np≥5 et n(1-p)≥5 ( [13], p. 310).
La différence p-π suit donc une loi Normale de moyenne nulle et de même écart-type. Comme π est inconnue, nous ne connaissons pas la valeur exacte de l’écart-type. Il existe deux possibilités pour l’approximer. On utilise le majorant (c’est-à-dire la plus grande valeur possible) de π(1-π) à savoir ¼. Ou bien, on remplace π par son estimation p pour le calcul de l’écart-type, ce qui est la méthode la plus courante.
Si l’on note z la valeur pour laquelle la fonction de répartition de la loi Normale centrée réduite est égale à 1-α/2, les bornes de l’intervalle de confiance de π sont alors égales à :
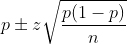
Cette méthode est la plus courante. Si elle produit des intervalles de confiance parfaitement centrés autour de la proportion observée, elle peut induire, pour des valeurs de p proches de 0 ou de 1, des intervalles dont une partie est inférieure à 0 ou supérieure à 1. Il est alors nécessaire de tronquer l’intervalle pour supprimer les valeurs aberrantes. Cette approximation n’est donc valable que pour une valeur de p proche de 50%.
Méthode de score (Wilson)
Comme pour la méthode standard, la méthode de score utilise la convergence de la loi Binomiale vers la loi Normale et approxime l’écart type en remplaçant π par p. Cette approche suggère que l’on peut obtenir un intervalle de confiance en prenant en compte les valeurs de π telles que :
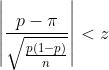
En élevant cette inégalité au carré puis en résolvant l’équation au second degré obtenue, on détermine alors les bornes de l’intervalle de confiance par la formule :
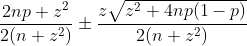
Cet intervalle de confiance n’est plus centré sur p et présente l’avantage de ne pas produire de valeur aberrante (inférieure à 0 ou supérieure à 1).
Pour plus de détails sur la résolution de l’équation, voir le mémoire de Patrick GAGNON ( [14], p. 12-13).
Correction de continuité
Il s’agit d’une correction, initialement proposée par YATES [15], pour tenir compte du passage d’une loi discrète à une loi continue. Chaque nombre entier x sera considéré comme couvrant l’intervalle allant de x-½ à x+½. Cela induit une légère modification des formules pour le calcul des intervalles de confiance.
Pour la méthode de WALD on obtient ainsi :
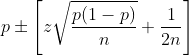
et pour la méthode de WILSON :

Choix d’une méthode
Différents auteurs ont comparé l’efficacité de plusieurs méthodes, dont les quatre présentées ici, ainsi que des méthodes de calcul plus complexes ( [16], [17], [18]). Si la méthode classique doit être évitée parce qu’il s’agit de la moins performante et qu’elle produit des valeurs aberrantes, la méthode WILSON de score avec correction de continuité est recommandée dans la mesure où ses performances sont presque équivalentes à celles de méthodes dites exactes et où son calcul est relativement aisé.
À noter que sous le logiciel R, la fonction prop.test() utilise par défaut les intervalles de Wilson avec correction de continuité.
Valeurs courantes de z
Nous avons noté z la valeur pour laquelle la fonction de répartition de la loi Normale centrée réduite est égale à 1-α/2. Le plus souvent, les intervalles de confiance calculés sont les intervalles à 95%, parfois 90% et plus rarement 99%.
Voici les valeurs de z correspondantes pour ces cas les plus fréquents :
- intervalle de confiance à 90 % : z= 1,64485362695 ≈ 1,645
- intervalle de confiance à 95 % : z= 1,95996398454 ≈ 1,960
- intervalle de confiance à 99 % : z= 2,57582930355 ≈ 2,576